
以下内容皆基于鱼书《深度学习入门基于python的理论与实现》
3层神经网络的实现
开始进行神经网络的实现,以下图的三层神经网络为例
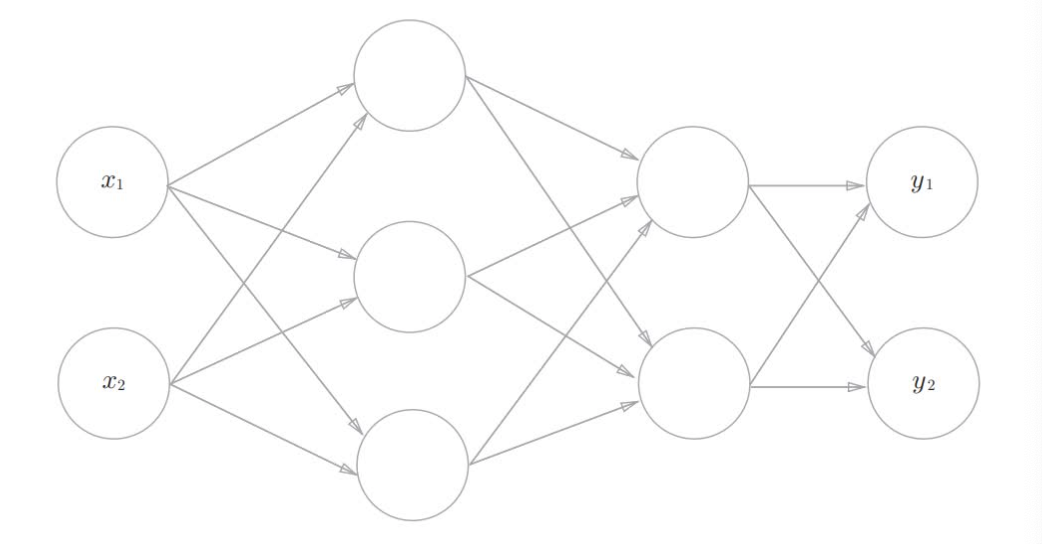
符号确认
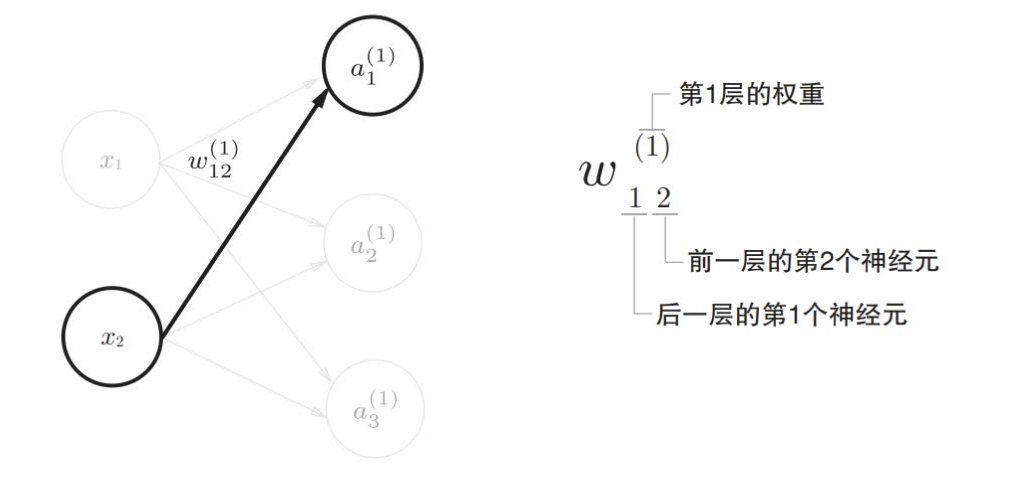
首先导入符号$w_{12}^{(1)}$, $a_{1}^{(1)}$等,如下图,权重和隐藏层的神经元右上角有一个"(1)",它表示权重和神经元的层号,此外,权重右下角的两个数字,它们是后一层的神经元和前一层的神经元的索引号,比如$w_{12}^{(1)}$表示前一层的第二个神经元$x_2$到后一层的第1个神经元$a_{1}^{(1)}$的权重。权重右下角按照"后一层的索引号、前一层的索引号"的顺序排序
各层间信号传递的实现
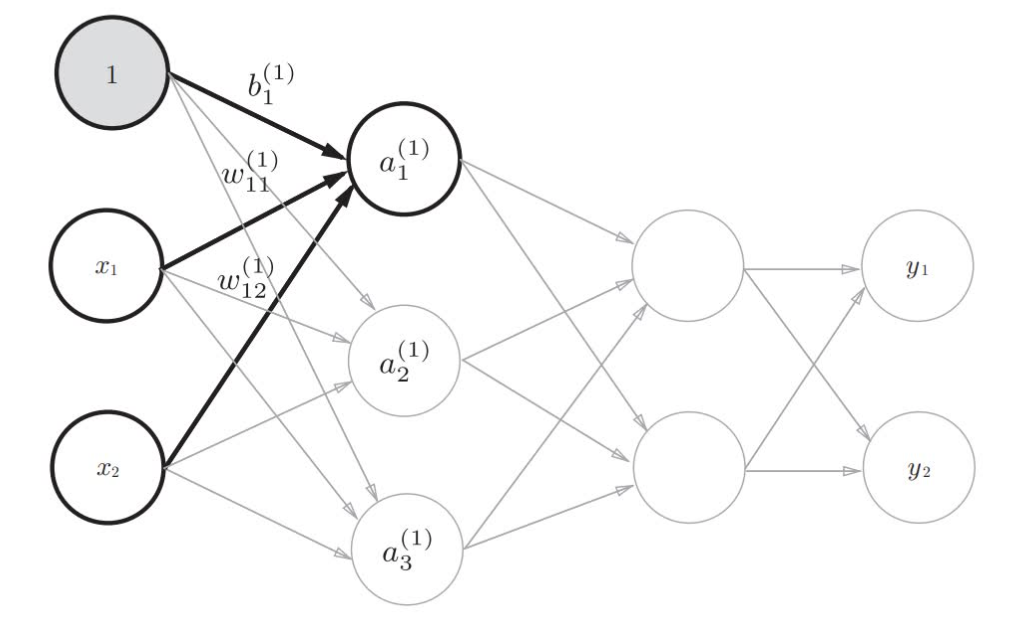
上图增加了表示偏置的神经元"1"。偏置的右下角的索引号只有一个因为前一层的偏置神经元只有一个
现在通过加权信号和偏置的和计算表示$a_{1}^{(1)}$。
$$ a_{1}^{(1)} = w_{11}^{(1)} x_{1} + w_{12}^{(1)} x_{2} + b_{1}^{(1)}\tag{8} $$如果用矩阵的乘法运算,则可以将第1层的加权和表示成下面的式(9)
$$ A^{(1)} = XW^{(1)} + B^{(1)} \tag{9} $$其中,$A^{(1)}$、$X$、$B^{(1)}$、$W^{(1)}$ 如下所示:
$$ A^{(1)} = \begin{pmatrix} a_{1}^{(1)} & a_{2}^{(1)} & a_{3}^{(1)} \end{pmatrix}, \quad X = \begin{pmatrix} x_1 & x_2 \end{pmatrix}, \quad B^{(1)} = \begin{pmatrix} b_{1}^{(1)} & b_{2}^{(1)} & b_{3}^{(1)} \end{pmatrix} $$$$ W^{(1)} = \begin{pmatrix} w_{11}^{(1)} & w_{21}^{(1)} & w_{31}^{(1)} \\ w_{12}^{(1)} & w_{22}^{(1)} & w_{32}^{(1)} \end{pmatrix} $$然后用NumPy多维数组来实现式(9),输入信号,权重,偏置设置成任意值
| |
W1是2x3的数组,X是元素个数为2的一维数组。这里,W1和X的对应维度的元素个数也保持了一致。
然后我们用python来实现第一层激活函数的计算过程
| |
这里说的sigmoid函数就是之前定义的那个,它会接收NumPy数组,然后返回元素个数相同的NumPy数组
下面我们来实现第1层到第2层的信号传递
| |
除了第一层的输出变成了第二层的输入,这个实现和刚才的一样
最后是第二层到输出层的信号传递,输出层的实现也和之前的实现基本相同,不过,最后的激活函数和之前的隐藏层有所不同
| |
这里定义了identity_function()函数(恒等函数),并将其作为输出层的激活函数。
代码总结
按照神经网络的实现惯例,把权重记为大写字母W1,其他都用小写字母表示
| |
这里定义了init_network()和forward()函数,init_network()函数会进行权重和偏置的初始化,并将它们保存在字典变量network中。forward()函数中则封装了将输入信号转换为输出信号的处理过程
输出层的设计
神经网络要根据情况改变输出层的激活函数。一般而言,回归问题用恒等函数,分类问题用softmax函数。
恒等函数和softmax函数
恒等函数会将输入按原样输出
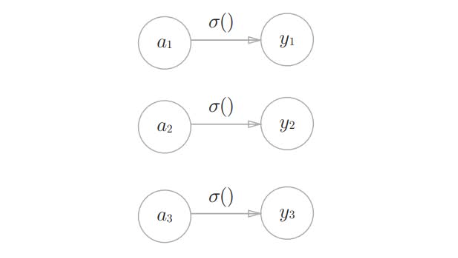
分类问题中的softmax函数可以用下面的式(10)表示
$$ y_k = \frac{\exp(a_k)}{\sum_{i=1}^{n} \exp(a_i)}\tag{10} $$上式表示假设输出层共有n个神经元,计算第k个神经元的输出$y_k$,如式(10)所示,softmax函数的分子是输入信号$a_k$的指数函数,分母是所有输入信号的指数函数的和
接下来来实现softmax函数。
| |
实现softmax函数时的注意事项
上面的softmax函数在计算上有一定的缺陷,就是溢出的问题,softmax函数的实现中要进行指数函数的运算,但是此时指数函数的值很容易变得非常大,比如$e^{1000}$的结果会返回一个表示无穷大大inf,在这些超大值之间进行除法运算,结果会出现不确定的情况,softmax可以像如下(11)改进
$$ \begin{aligned} y_k &= \frac{\exp(a_k)}{\sum_{i=1}^{n} \exp(a_i)} = \frac{C \exp(a_k)}{C \sum_{i=1}^{n} \exp(a_i)} \\[6pt] &= \frac{\exp(a_k + \log C)}{\sum_{i=1}^{n} \exp(a_i + \log C)} \\[6pt] &= \frac{\exp(a_k + C')}{\sum_{i=1}^{n} \exp(a_i + C')} \end{aligned} \tag{11} $$先在分子和分母上都乘以C(一个任意的常数),然后把C移动到指数函数中,记为$log C$。最后把$logC$替换为另外一个符号$C'$
综上,我们来实现下最终版的softmax函数
| |
softmax函数的特征
- 输出总和为1,因为这个性质我们才可以把softmax函数的输出解释为“概率”
- 使用了softmax函数各个元素之间的大小关系也不会改变,因为exp是单调递增的
- 神经网络一般只会把输出值最大的神经元所对应的类别作为识别结果。使用softmax函数输出值最大的神经元的位置也不会变,因此输出层的softmax函数一般会被忽略
输出层的神经元数量
输出层的神经元数量需要根据待解决的问题来决定。对于分类问题,输出层的神经元数量一般设定为类别的数量。比如,对于某个输入图像,预测是图中的数字0到9中的哪个的问题,可以把输出层的神经元设定为10个,然后把这十个神经元按照从上到下,从0-9依次编号,并且值用不同的灰度表示,颜色越深,输出的值就越大
手写数字识别
开始解决实际问题,假设学习已经全部结束,我们使用学习到的参数,先实现神经网络的“推理处理”。这个推理处理也称为神经网络的前向传播
MNIST数据集
MNIST数据集是由0到9的数字图像构成的。训练图像有6万张,测试图像有1万张,这些图像可以用于学习与推理。MNIST数据集的一般使用方法是,先用训练图像进行学习,再用学习到的模型度量能在能在多大程度上对测试图像进行正确的分类
MNIST的图像数据是28像素x28像素的灰度图像(1通道),各个像素的取值在0到255之间。每个图像都相应地标有“7” “2” “1”等标签。
从数据中学习
数据驱动
如何实现数字“5”的识别,如果要设计一个能将5正确分类的程序