SMO算法
John Platt 发明的 SMO(序列最小优化)算法提供了一种有效的方法来解决由 SVM 的推导得到的对偶问题。部分是为了激发 SMO 算法,部分是因为它本身很有趣,让我们首先讨论坐标上升算法。
坐标上升
考虑尝试解决无约束的优化问题:
$$ \max_{\alpha} W(\alpha_1, \alpha_2, \ldots, \alpha_m) $$在这里,我们将 $W$ 视为参数 $\alpha_i$ 的某个函数,现在忽略此问题与 SVM 之间的任何关系。我们已经看到了两种优化算法,梯度上升和牛顿方法。我们将在这里考虑的新算法称为坐标上升:
迭代直至收敛:
- 对 $i = 1, \ldots, m$, $$ \alpha_i := \arg\max_{\hat{\alpha}_i} W(\alpha_1, \ldots, \alpha_{i-1}, \hat{\alpha}_i, \alpha_{i+1}, \ldots, \alpha_m) $$
因此,在该算法的最内层循环中,除了一些固定的 $\alpha_j$ 之外,我们将保持所有变量,并且仅针对参数 $\alpha_i$ 重新优化 $W$。在这里给出的这个方法的版本中,内循环按 $\alpha_1, \alpha_2, \ldots, \alpha_m, \alpha_1, \alpha_2, \ldots$ 的顺序重新优化变量(一个更复杂的版本可能会选择其他顺序;例如,我们可以选择使 $W(\alpha)$ 获得最大增长的变量)。
当函数 $W$ 碰巧具有内循环中的 “arg max” 可以有效地执行的形式时,那么坐标上升是相当有效的算法。这是一张坐标上升的图片:
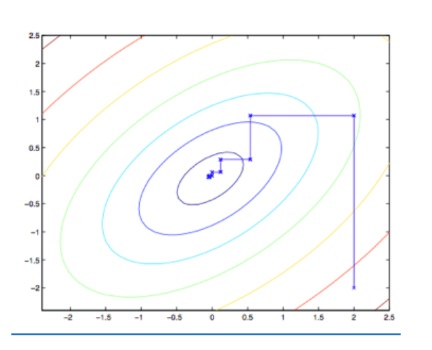
SMO
我们通过对 SMO 算法的简单推导来结束对 SVM 的讨论。
这是我们想要解决的(对偶)优化问题:
$$ \max_{\alpha} \; W(\alpha) = \sum_{i=1}^{m} \alpha_i - \frac{1}{2} \sum_{i,j=1}^{m} y^{(i)} y^{(j)} \alpha_i \alpha_j \langle x^{(i)}, x^{(j)} \rangle $$$$ \text{s.t. } 0 \le \alpha_i \le C,\; i = 1, \ldots, m \tag{18} $$$$ \sum_{i=1}^{m} \alpha_i y^{(i)} = 0 \tag{19} $$假设我们有一组满足约束条件 (18)–(19) 的 $\alpha_i$。现在,假设我们想要保持 $\alpha_2, \ldots, \alpha_m$ 固定,并采取坐标上升法,并关于 $\alpha_1$ 重新优化目标。我们可以取得任何进展吗?答案是否定的,因为约束 (19) 确保了
$$ \alpha_1 y^{(1)} = - \sum_{i=2}^{m} \alpha_i y^{(i)} $$或者,通过将两边乘以 $y^{(1)}$,我们等价地有
$$ \alpha_1 = - y^{(1)} \sum_{i=2}^{m} \alpha_i y^{(i)} $$(这一步使用了 $y^{(1)} \in {-1, 1}$ 因此 $(y^{(1)})^2 = 1$。所以如果我们保持保持 $\alpha_2, \ldots, \alpha_m$ 固定,那么 $\alpha_1$ 完全由其他 $\alpha_i$ 确定,那么我们就不能在不违反优化问题中的约束 (19) 的情况下对 $\alpha_1$ 进行任何改变。)
因此,如果我们想要更新 $\alpha_i$ 中某些项,我们必须同时更新它们中的至少两个以便保持满足约束。这激发了 SMO 算法,它简单地执行以下操作:
- 重复直至收敛:
- 选择一对 $\alpha_i$ 和 $\alpha_j$ 进行下一次更新(选择在全局最大值上取得最大增量的两个坐标)。
- 关于 $\alpha_i$ 和 $\alpha_j$ 重新优化 $W(\alpha)$,同时保持所有其他 $\alpha_k\ (k \ne i,j)$ 固定。
为了测试该算法的收敛性,我们可以检查 KKT 条件(公式 14–16)是否在某个 tol 范围内满足。这里,tol 是收敛容差参数,并且通常设置为约 0.01 至 0.001。(有关详细信息,请参论文和伪代码。)
SMO 是一种有效算法的关键原因对 $\alpha_i, \alpha_j$ 的更新可以有效地进行。现在让我们简要推导高效更新的主要思路。
假设我们目前有一些 $\alpha_i$ 满足约束条件 (18)–(19),并假设我们决定保持 $\alpha_3, \ldots, \alpha_m$ 固定,并且想要关于 $\alpha_1$ 和 $\alpha_2$(满足约束条件)重新优化 $W(\alpha_1, \alpha_2, \ldots, \alpha_m)$。由等式 (19),我们有
$$ \alpha_1 y^{(1)} + \alpha_2 y^{(2)} = - \sum_{i=3}^{m} \alpha_i y^{(i)} $$由于右侧是固定的(因为我们已经固定了 $\alpha_3, \ldots, \alpha_m$),我们可以用某个常数 $\xi$ 表示这项:
$$ \alpha_1 y^{(1)} + \alpha_2 y^{(2)} = \xi $$因此,我们可以将对 $\alpha_1$ 和 $\alpha_2$ 的约束描述如下:
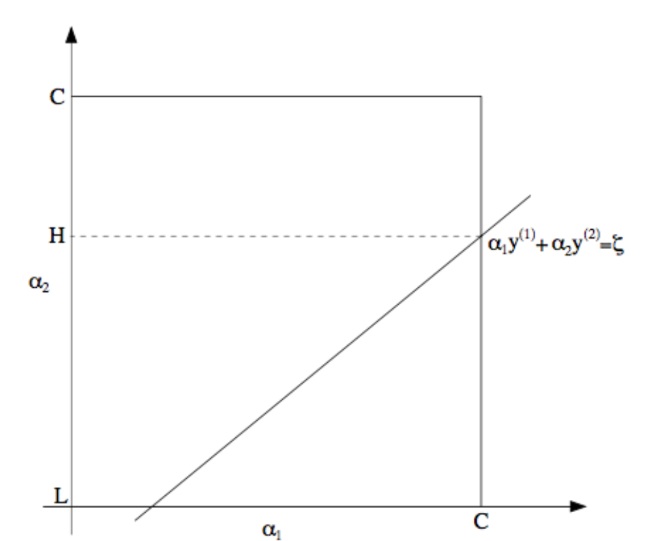
根据约束 (18),我们知道 $\alpha_1$ 和 $\alpha_2$ 必须位于所示的框 $[0, C] \times [0, C]$ 内。还绘制了直线 $\alpha_1 y^{(1)} + \alpha_2 y^{(2)} = \xi$,其中 $\alpha_1$ 和 $\alpha_2$ 必须在该直线上。还要注意,从这些约束中,我们知道 $L \le \alpha_2 \le H$;否则,$(\alpha_1, \alpha_2)$ 不能同时满足框和直线约束。在这个例子中,$L = 0$。但是根据直线 $\alpha_1 y^{(1)} + \alpha_2 y^{(2)} = \xi$ 的样子,这不是必然的情况;但更一般地,在 $\alpha_2$ 的允许值上将存在某个下限 $L$ 和某个上限 $H$,这将确保 $\alpha_1, \alpha_2$ 位于框 $[0, C] \times [0, C]$ 内。
使用等式 (20),我们也可以将 $\alpha_1$ 写为 $\alpha_2$ 的函数:
$$ \alpha_1 = (\xi - \alpha_2 y^{(2)}) y^{(1)} $$(我们再次使用 $y^{(1)} \in {-1, 1}$ 的事实,因此 $(y^{(1)})^2 = 1$。)因此,可以写出目标函数 $W(\alpha)$:
$$ W(\alpha_1, \alpha_2, \ldots, \alpha_m) = W((\xi - \alpha_2 y^{(2)}) y^{(1)}, \alpha_2, \ldots, \alpha_m) $$将 $\alpha_3, \ldots, \alpha_m$ 视为常数,可以验证这是关于 $\alpha_2$ 的二次函数。即,对于某些 $a, b, c$,可以以 $a\alpha_2^2 + b\alpha_2 + c$ 的形式表示。如果我们忽略“框”约束 (18)(或等效地,$L \le \alpha_2 \le H$),那么我们可以通过将其导数设为零并求解来轻松地最大化该二次函数。我们将 $\alpha_2^{\text{new, unclipped}}$ 表示 $\alpha_2$ 的结果值。如果我们想要相对于 $\alpha_2$ 最大化 $W$ 但受制于框约束,我们可以得到(利用二次函数的性质):
$$ \alpha_2^{\text{new}} = \begin{cases} H & \text{如果 } \alpha_2^{\text{new, unclipped}} > H \\ \alpha_2^{\text{new, unclipped}} & \text{如果 } L \le \alpha_2^{\text{new, unclipped}} \le H \\ L & \text{如果 } \alpha_2^{\text{new, unclipped}} < L \end{cases} $$最后,找到了 $\alpha_2^{\text{new}}$,我们可以使用公式 (20) 找到 $\alpha_1^{\text{new}}$ 的最优值。
还有一些非常简单的细节,可以在 Platt 的论文中了解:一个是用于选择下一个 $\alpha_i, \alpha_j$ 进行更新的启发式选择;另一个是在运行 SMO 算法时如何更新 $b$。
学习理论
偏差/方差的权衡
首先看下图:
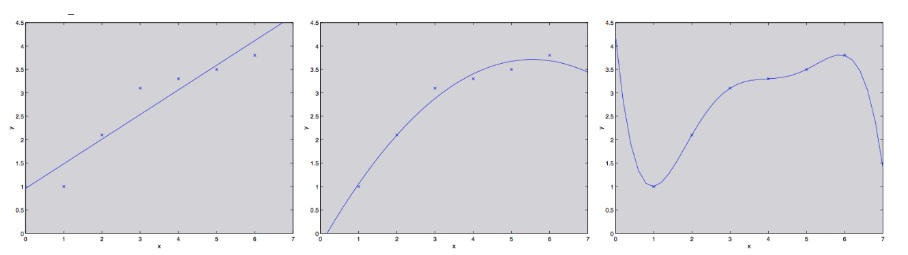
我们的目标函数是二次的,第一张图采用一次函数拟合,第三张图采用五次函数拟合,这两种情况下的泛化误差都很大,但是产生的原因是不同的。第一张图在训练集上误差就很大,并且无论训练集有多少数据,得到的效果都不会太好,因为一次函数很难捕捉二次函数的特点,这种情形称为欠拟合,偏差很大;第三张图中训练集上的误差为 0,这种情形往往是只捕捉到训练数据的模式,但是没有捕捉到 $x, y$ 更广泛的模式,如果我们计算不在训练集中的数据的损失函数,会发现损失往往非常大,这种情形称为过拟合,方差很大。在实际操作过程中,我们需要对偏差、方差进行权衡,既不能使用太简单的模型(欠拟合),也不能使用太复杂的模型(过拟合)。
预先准备
这里介绍两个后续讨论需要用到的引理
引理
$A_1, A_2, \ldots, A_k$ 是 $k$ 个不同事件,那么
$$ P(A_1 \cup \cdots \cup A_k) \le P(A_1) + \cdots + P(A_k) $$非常熟悉的公理,不予证明
引理
设 $Z_1, \ldots, Z_m$ 是 $m$ 个独立同分布,服从伯努利分布 $b(1, \phi)$,即 $P(Z_i = 1) = \phi,; P(Z_i = 0) = 1 - \phi$,令 $\hat{\phi} = \frac{1}{m} \sum_{i=1}^{m} Z_i$,那么对任意固定 $\gamma > 0$,有
$$ P(|\hat{\phi} - \phi| > \gamma) \le 2 \exp(-2\gamma^2 m) $$这里老师没给出证明,我自己之前写过一个初等证明——传送门,后面会整理老师给的补充材料里的证明,这里先使用这个结论。
为了简化讨论,这里将问题限制在二元分类问题中,即 $y \in {0,1}$,假设训练集 $S = {(x^{(i)}, y^{(i)}); i = 1, \ldots, m}$,$(x^{(i)}, y^{(i)})$ 来自同一分布 $\mathcal{D}$ 的样本,对于一个假设 $h$,定义训练误差(或经验风险):
$$ \hat{\epsilon}(h) = \frac{1}{m} \sum_{i=1}^{m} 1\{h(x^{(i)}) \ne y^{(i)}\} $$不难看出,上述量即为 $h$ 在训练集中误分类的比例。如果我们想明确表达 $\hat{\epsilon}(h)$ 和某个训练集 $S$ 的关系,我们可以写为 $\hat{\epsilon}_S(h)$。此外,我们还定义泛化误差为:
$$ \epsilon(h) = P_{(x,y)\sim \mathcal{D}}(h(x) \ne y) $$即为从分布 $\mathcal{D}$ 中抽取一个样本 $(x,y)$,$h$ 分类错误的概率。我们的学习算法实际上是在做经验风险最小化(ERM),即找到
$$ \hat{h} = \arg\min_{h \in \mathcal{H}} \hat{\epsilon}(h) $$有限个假设的情况
我们先开始考虑假设类有限的学习问题,假设 $\mathcal{H} = {h_1, \ldots, h_k}$ 有 $k$ 个将 $x$ 映射到 ${0,1}$ 的函数,经验风险最小化即为从 $k$ 个假设中选择训练误差最小的函数。
现在任取 $h_i \in \mathcal{H}$,对于 $\mathcal{D}$ 中样本 $(x,y)$,考虑伯努利随机变量 $Z = 1{h_i(x) \ne y}$,类似地定义 $Z_j = 1{h_i(x^{(j)}) \ne y^{(j)}}$,
由于我们的样本是从 $\mathcal{D}$ 获得的独立同分布随机变量,所以 $Z, Z_j$ 同分布。此外,训练误差可以写为
$$ \hat{\epsilon}(h_i) = \frac{1}{m} \sum_{j=1}^{m} Z_j $$因此,$\hat{\epsilon}(h_i)$ 是 $m$ 个随机变量的均值,这些随机变量独立同分布,都来自均值为 $\epsilon(h)$ 的伯努利分布,所以我们可以使用 Hoeffding 不等式,得到
$$ P(|\epsilon(h_i) - \hat{\epsilon}(h_i)| > \gamma) \le 2 \exp(-2\gamma^2 m) $$这说明对于某个特定的 $h_i$,当 $m$ 很大时,其训练误差和泛化误差非常接近。但是我们不仅仅希望 $\epsilon(h_i)$ 和 $\hat{\epsilon}(h_i)$ 很接近,我们希望对每个 $h \in \mathcal{H}$ 上述事实都成立。令 $A_i$ 表示事件 $|\epsilon(h_i) - \hat{\epsilon}(h_i)| > \gamma$,我们已经证明了
$$ P(A_i) \le 2 \exp(-2\gamma^2 m) $$因此使用第一个引理可得
$$ \begin{aligned} P(\exists h_i \in \mathcal{H}, |\epsilon(h_i) - \hat{\epsilon}(h_i)| > \gamma)&= P(A_1 \cup \cdots \cup A_k) \\&\le \sum_{i=1}^{k} P(A_i) \\&\le \sum_{i=1}^{k} 2 \exp(-2\gamma^2 m) \\&\le 2k \exp(-2\gamma^2 m) \end{aligned} $$两边同时减 1 得
$$ P(\forall h_i \in \mathcal{H}, |\epsilon(h_i) - \hat{\epsilon}(h_i)| \le \gamma)\ge 1 - 2k \exp(-2\gamma^2 m) $$上述不等式的含义为,有至少 $1 - 2k \exp(-2\gamma^2 m)$ 的概率,对任意 $h \in \mathcal{H}$,$\epsilon(h)$ 落在 $\hat{\epsilon}(h)$ 附近的 $\gamma$ 范围内,这被称为一致收敛,因为上界对每个 $h \in \mathcal{H}$ 成立。注意上述结论中有 3 个重要的量——$m, \gamma$ 以及概率,其中一个量可以用另外两个量来约束。
例如考虑如下问题,给定 $\gamma, \delta$,$m$ 需要多大,才能保证至少有 $1 - \delta$ 概率使得训练误差在泛化误差 $\gamma$ 范围内,我们令
$$ 1 - 2k \exp(-2\gamma^2 m) \ge 1 - \delta $$可得
$$ 2k \exp(-2\gamma^2 m) \le \delta\;\Rightarrow\;m \ge \frac{1}{2\gamma^2} \log \frac{2k}{\delta} $$这说明当 $m \ge \frac{1}{2\gamma^2} \log \frac{2k}{\delta}$ 时,我们有 $1 - \delta$ 的概率使得训练误差在泛化误差 $\gamma$ 范围内。
类似的,我们可以固定 $m$ 和 $\delta$,在之前的问题中解出 $\gamma$,令
$$ 1 - 2k \exp(-2\gamma^2 m) \ge 1 - \delta $$可得
$$ \gamma \ge \sqrt{\frac{1}{2m} \log \frac{2k}{\delta}} $$取 $\gamma = \sqrt{\frac{1}{2m} \log \frac{2k}{\delta}}$, 我们有 $1 - \delta$ 的概率使得
$$ |\epsilon(h) - \hat{\epsilon}(h)| \le \sqrt{\frac{1}{2m} \log \frac{2k}{\delta}} $$现在假设一致收敛成立,即 $|\epsilon(h) - \hat{\epsilon}(h)| \le \gamma$ 对每个 $h \in \mathcal{H}$,接下来证明 $\hat{h} = \arg\min_{h \in \mathcal{H}} \hat{\epsilon}(h)$ 的泛化误差上界。定义 $h’ = \arg\min_{h \in \mathcal{H}} \epsilon(h)$,注意 $h’$ 为最优假设,那么
$$ \begin{aligned} \epsilon(\hat{h})&\le \hat{\epsilon}(\hat{h}) + \gamma \\&\le \hat{\epsilon}(h') + \gamma \\&\le \epsilon(h') + 2\gamma \end{aligned} $$第一个和第三个不等号是因为 $|\epsilon(h) - \hat{\epsilon}(h)| \le \gamma$ 对每个 $h \in \mathcal{H}$ 都成立,第二个不等号是因为 $\hat{h} = \arg\min_{h \in \mathcal{H}} \hat{\epsilon}(h)$,所以如果一致收敛成立,那么 $\hat{h}$ 的泛化误差最多和最优假设相差 $2\gamma$。
将以上内容总结为定理:
定理
令 $|\mathcal{H}| = k$,$m$ 和 $\delta$ 为任意固定值,那么至少有 $1 - \delta$ 的概率,我们有:
$$ \epsilon(\hat{h}) \le \left( \min_{h \in \mathcal{H}} \epsilon(h) \right)+ 2 \sqrt{\frac{1}{2m} \log \frac{2k}{\delta}} $$结合之前的讨论,固定 $\gamma, \delta$,当 $m \ge \frac{1}{2\gamma^2} \log \frac{2k}{\delta}$ 时,一致收敛成立,因此:
$$ \epsilon(\hat{h}) \le \left( \min_{h \in \mathcal{H}} \epsilon(h) \right) + 2\gamma $$推论
令 $|\mathcal{H}| = k$,$\gamma$ 和 $\delta$ 为任意的固定值,那么要使
$$ \epsilon(\hat{h}) \le \left( \min_{h \in \mathcal{H}} \epsilon(h) \right) + 2\gamma $$有大于等于 $1 - \delta$ 的概率发生,只要有
$$ m \ge \frac{1}{2\gamma^2} \log \frac{2k}{\delta}= O\left(\frac{1}{\gamma^2} \log \frac{k}{\delta}\right) $$