无限个假设的情况
介绍之前给出一些定义。
给定集合 $S = {x^{(1)}, \ldots, x^{(d)}}$,其中 $x^{(i)} \in \mathcal{X}$,我们称 $\mathcal{H}$ 打散(shatter)$S$ 如果 $\mathcal{H}$ 能实现 $S$ 上任意一种标记。即对任意标签集 ${y^{(1)}, \ldots, y^{(d)}}$,存在 $h \in \mathcal{H}$ 使得 $h(x^{(i)}) = y^{(i)}$。给定集合 $\mathcal{H}$,定义 VC 维(Vapnik–Chervonenkis dimension)为 $\mathcal{H}$ 能打散的最大集合的大小,用 $VC(\mathcal{H})$ 表示,如果 $\mathcal{H}$ 能打散任意数量的集合,那么 $VC(\mathcal{H}) = \infty$。
二维线性分类器($h(x) = 1{\theta_0 + \theta_1 x_1 + \theta_2 x_2 \ge 0}$)的假设类 $\mathcal{H}$ 能否将上述情形打散呢?答案是肯定的,如下图所示:
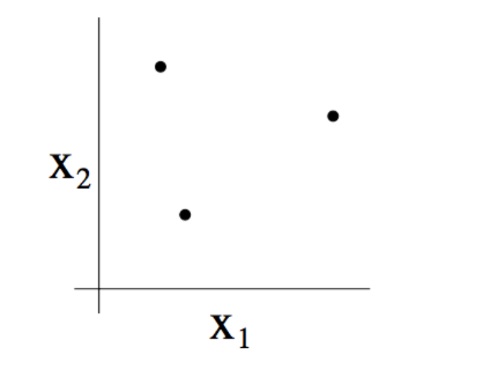
此外,不难看出 $\mathcal{H}$ 无法打散 4 个点的情形,所以 $VC(\mathcal{H}) = 3$。
需要注意的是,尽管 $VC(\mathcal{H}) = 3$,但仍然有 3 个点的情形无法被打散,如下图所示:
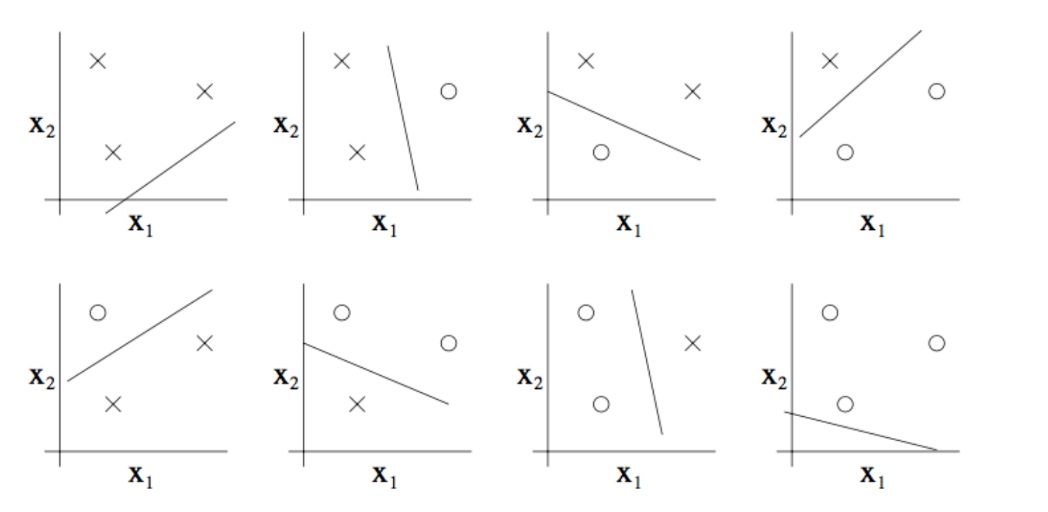
换句话说,在 VC 维的定义下,为了证明 $VC(\mathcal{H}) \ge d$,只要证明至少有一个规模为 $d$ 的集合能被打散即可。
接下来给出学习理论中的重要定理:
定理
给定 $\mathcal{H}$,令 $d = VC(\mathcal{H})$,那么有至少 $1 - \delta$ 的概率,对于任意 $h \in \mathcal{H}$,
$$ |\epsilon(h) - \hat{\epsilon}(h)| \le O\left(\sqrt{\frac{d}{m} \log \frac{m}{d} + \frac{1}{m} \log \frac{1}{\delta}}\right) $$因为,至少有 $1 - \delta$ 的概率,我们有:
$$ \epsilon(\hat{h}) \le \epsilon(h^*) + O\left(\sqrt{\frac{d}{m} \log \frac{m}{d} + \frac{1}{m} \log \frac{1}{\delta}}\right) $$换句话说,如果假设类的 VC 维有限,那么当 $m$ 比较大的时候一致收敛就会成立,和之前一样,这就能让我们用 $\epsilon(h^*)$ 的形式给出 $\epsilon(h)$ 的上界。我们还有如下推论:
推论
为了让 $|\epsilon(h) - \hat{\epsilon}(h)| \le \gamma$ 对于任意 $h \in \mathcal{H}$ 有至少 $1 - \delta$ 的概率成立(从而可以推出 $\epsilon(\hat{h}) \le \epsilon(h^*) + 2\gamma$),只要满足
$$ m = O_{\gamma,\delta}(d) $$换句话说,要使假设类 $\mathcal{H}$ 的表现比较好,我们需要和其 VC 维线性关系的数据,实际中,VC 维往往和参数数量呈线性关系,所以一般情况下训练样本数要和参数数量呈线性关系。
备注:有关 VC 维的部分这里比较简略,可以参考相关课程或教材。
正则化与模型选择
这一讲主要介绍如何权衡偏差与方差,选择适合的模型以及参数
交叉验证
假设给定训练集 $S$,我们已经了解经验风险最小化,来看下面一个使用经验风险最小化推导的算法:
- 在 $S$ 上训练每个模型 $M_i$,得到假设 $h_i$
- 选择具有最小训练误差的假设
这个算法是没有用的。考虑选择多项式的次数,多项式次数越高,那么模型在训练集上的表现就越好,因此就有较小的训练误差。所以这个模型会选择一个高方差、高次数的多项式模型,这通常是一个糟糕的选择。
现在有一个效果更好的算法,叫做保留交叉验证(hold-out cross validation),也叫做简单交叉验证(simple cross validation),步骤如下:
- 将 $S$ 随机分为 $S_{\text{train}}$(一般为 70%)和 $S_{\text{cv}}$(剩余的 30%),这里 $S_{\text{cv}}$ 被称为保留交叉验证集
- 在 $S_{\text{train}}$ 训练每个模型 $M_i$ 获得 $h_i$
- 选择在交叉验证集上误差 $\hat{\epsilon}{S{\text{cv}}}(h_i)$ 最小的假设 $h_i$
通过在我们没有训练过的样本 $S_{\text{cv}}$ 上做测试,我们得到了对 $h_i$ 的真实泛化误差的更好估计,而且可以选择具有最小泛化误差估计的假设。通常,交叉验证集合的比例选在 $\frac{1}{4} - \frac{1}{3}$ 之间,30% 是一个经典的选择。
另一种选择是,将步骤 3 替换为根据 $\arg\min_i \hat{\epsilon}{S{\text{cv}}}(h_i)$ 选择模型 $M_i$,然后在全体数据 $S$ 上重新训练 $M_i$。这通常是一个好方法。
保留交叉验证的劣势在于浪费了约 30% 的数据,即使我们选择在全体数据上重新训练模型,我们仍然是在 $0.7m$ 的数据上找到最优模型,因为我们每次只是在 $0.7m$ 的数据上训练模型。当数据充足或廉价时问题不大,但数据较少时需要更好的方法。
下面是一个方法,被称为 $k$ 折交叉验证($k$-fold cross validation),每次保留的数据更少:
- 将 $S$ 随机划分为 $k$ 个不相交的子集,每个子集有 $m/k$ 个训练样本,记为 $S_1, \ldots, S_k$
- 对每个模型 $M_i$,进行如下评估:
- 对 $j = 1, \ldots, k$
- 在 $S_1 \cup \cdots \cup S_{j-1} \cup S_{j+1} \cup \cdots \cup S_k$ 上训练 $M_i$ 得到 $h_{ij}$
- 在 $S_j$ 上测试 $h_{ij}$,得到 $\hat{\epsilon}{S_j}(h{ij})$
- 计算 $\hat{\epsilon}{S_j}(h{ij})$ 的平均值来估计模型 $M_i$ 的泛化误差
- 对 $j = 1, \ldots, k$
- 选择具有最小泛化误差估计的模型 $M_i$,在 $S$ 上重新训练模型
$k$ 的经典选择是 10。尽管每次验证的数据只有 $1/k$,但计算成本更高,因为需要训练 $k$ 次。
当数据非常少时,可以选择 $k = m$,即每次只留下一个样本作为测试,这种方法称为留一法交叉验证(leave-one-out cross validation)。
特征选择
一种特殊的模型选择方法被称为特征选择。设想一个监督学习问题,其特征数 $n$ 非常大(例如 $n \gg m$),但实际上只有一部分特征与任务相关。
在这样的背景下,我们可以使用特征选择算法减少特征数量。给定 $n$ 个特征,有 $2^n$ 个可能的特征子集,因此特征选择问题可以看作在 $2^n$ 个模型中选择。
由于 $2^n$ 通常非常大,我们使用启发式搜索算法,例如前向搜索:
- 初始化 $\mathcal{F} = \emptyset$
- 重复:
- 对于 $i = 1, \ldots, n$,如果 $i \notin \mathcal{F}$,令 $\mathcal{F}_i = \mathcal{F} \cup {i}$,并使用交叉验证评估 $\mathcal{F}_i$
- 令 $\mathcal{F}$ 为表现最好的特征子集
- 输出整个过程中表现最好的特征子集
也可以使用反向搜索,从 $\mathcal{F} = {1, \ldots, n}$ 开始,每次移除一个特征。
包装器特征选择(wrapper methods)通常效果较好,但计算成本较高。
另一类方法是过滤式特征选择(filter methods),其计算成本更低。我们可以定义一个评分函数 $S(i)$ 来衡量特征 $x_i$ 的重要性,例如互信息:
$$ \mathrm{MI}(x_i, y) = \sum_{x_i \in \{0,1\}} \sum_{y \in \{0,1\}} p(x_i, y)\log \frac{p(x_i, y)}{p(x_i)p(y)} $$互信息也可以表示为 KL 散度:
$$ \mathrm{MI}(x_i, y) = \mathrm{KL}(p(x_i, y) \,\|\, p(x_i)p(y)) $$KL 散度衡量两个分布的差异。如果 $x_i$ 与 $y$ 独立,则互信息为 0;否则互信息越大表示相关性越强。
最后,可以根据评分函数对特征排序,并选择前 $k$ 个特征。