
$k$ 均值聚类算法
在聚类问题中,我们得到训练集 ${x^{(i)}, \ldots, x^{(m)}}$,然后想把数据分成几个相关的“簇”。这里 $x^{(i)} \in \mathbb{R}^n$,但是没有有 $y^{(i)}$。所以这是个非监督学习问题。
$k$ 均值聚类算法如下:
- 随机初始化 $C$ 个聚类中心 $\mu_1, \ldots, \mu_k \in \mathbb{R}^n$
- 重复如下操作直到收敛:
对每个 $i$,令
$$ c^{(i)} := \arg\min_j \|x^{(i)} - \mu_j\|^2 $$对每个 $j$,令
$$ \mu_j := \frac{\sum_{i=1}^{m} 1\{c^{(i)} = j\}x^{(i)}}{\sum_{i=1}^{m} 1\{c^{(i)} = j\}} $$
算法的内层循环重复两个步骤:(i) 把每个训练样本 $x^{(i)}$ “分配”给距离最近的聚类中心;(ii) 将聚类中心 $\mu_j$ 移动到所分配的样本点的中心。下图展示了$k$ 值均类算法的过程
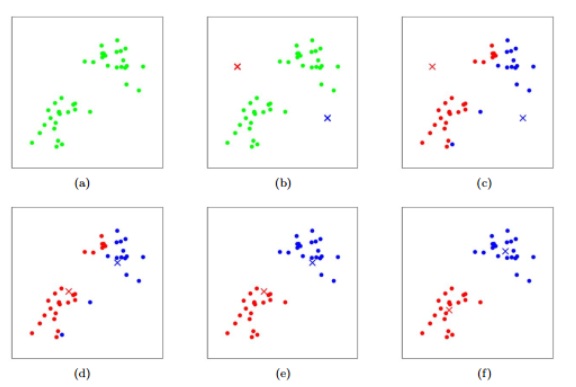
$k$ 均值聚类法是否保证收敛呢?是的,至少从某种意义上说。特别地,我们定义如下损失函数(distortion function):
$$ J(c,\mu) = \sum_{i=1}^{m} \|x^{(i)} - \mu_{c^{(i)}}\|^2 $$因此,$J$ 衡量每个训练样本 $x^{(i)}$ 和其聚类中心 $\mu_{c^{(i)}}$ 距离的平方和。可以看出 $k$ 均值聚类算法就是 $J$ 坐标下降的过程。特别地,$k$ 均值聚类算法内层的循环重复对 $J$ 进行最小化,先固定 $\mu$,根据 $c$ 来最小化 $J$,再固定 $c$,根据 $\mu$ 来进行最小化。因此 $J$ 一定单调递减,并且 $J$ 的值一定收敛。
损失函数 $J$ 是一个非凸函数,所以 $J$ 的坐标下降法无法保证收敛到全局最小值。换句话说,$k$ 均值聚类可能只是局部最优。尽管如此,$k$ 均值聚类通常效果很好并且给出很好地聚类。但是如果你担心陷入比较差的局部最小值,一种常用的方法是多次运行 $k$ 均值聚类(对聚类中心 $\mu_j$ 使用不同的随机初始值)。然后,从所有不同的聚类结果中选择提供最小损失函数的 $J(c,\mu)$ 的聚类。
高斯混合模型和 EM 算法
在这部分的讲义中,我们将使用 EM(Expectation-Maximization)算法进行密度估计。
假设我们像往常一样给定训练集 ${x^{(i)}, \ldots, x^{(m)}}$。因为我们在讨论非监督学习,这些数据点没有标签。
我们希望用特定的联合分布 $p(x^{(i)}, z^{(i)}) = p(x^{(i)} \mid z^{(i)})p(z^{(i)})$ 来对数据进行建模。这里,$z^{(i)} \sim$ 多项分布 $(\phi)$(其中 $\phi_j \ge 0, \sum_{j=1}^{k} \phi_j = 1$,参数 $\phi_j = p(z^{(i)} = j)$),$x^{(i)} \mid z^{(i)} = j \sim \mathcal{N}(\mu_j, \Sigma_j)$。令 $k$ 表示 $z^{(i)}$ 可以取值的数量。因此,我们的模型假定每个 $x^{(i)}$ 是按如下方式生成的:从 ${1, \ldots, k}$ 中随机选择 $z^{(i)}$,然后 $x^{(i)}$ 是从依赖 $z^{(i)}$ 的 $k$ 个高斯分布中得到的。这个模型被称为高斯混合模型。此外,注意到 $z^{(i)}$ 是隐藏变量,这意味着他们是不可见的。这将使我们的估计问题更加困难。
我们模型的参数是 $\phi, \mu$ 和 $\Sigma$。为了估计他们,我们可以把数据的似然函数按如下方式写出:
$$ l(\phi, \mu, \Sigma)= \sum_{i=1}^{m} \log p(x^{(i)}; \phi, \mu, \Sigma)= \sum_{i=1}^{m} \log \sum_{z^{(i)}=1}^{k} p(x^{(i)} \mid z^{(i)}; \mu, \Sigma)p(z^{(i)}; \phi) $$但是,如果我们将上述方程的导数置为 0 并尝试解出参数,我们将发现无法得到参数的最大似然估计的解析形式(closed form)。
随机变量 $z^{(i)}$ 表示每个 $x^{(i)}$ 来自哪个高斯分布中的哪个,注意到如果我们知道 $z^{(i)}$ 是什么,上述最大似然问题将很简单。特别地,我们可以按如下方式写出最大似然函数
$$ l(\phi, \mu, \Sigma)= \sum_{i=1}^{m} \log p(x^{(i)} \mid z^{(i)}; \mu, \Sigma) + \log p(z^{(i)}; \phi) $$关于 $\phi, \mu, \Sigma$ 求上述的最大值可以得到参数:
$$ \phi_j = \frac{1}{m} \sum_{i=1}^{m} 1\{z^{(i)} = j\}, $$$$ \mu_j = \frac{\sum_{i=1}^{m} 1\{z^{(i)} = j\}x^{(i)}}{\sum_{i=1}^{m} 1\{z^{(i)} = j\}}, $$$$ \Sigma_j= \frac{\sum_{i=1}^{m} 1\{z^{(i)} = j\}(x^{(i)} - \mu_j)(x^{(i)} - \mu_j)^T} {\sum_{i=1}^{m} 1\{z^{(i)} = j\}} $$事实上,我们发现如果 $z^{(i)}$ 已知,那么最大似然估计几乎等同于我们已经讨论过的高斯判别分析模型中对参数的估计,除了 $z^{(i)}$ 在此处扮演类别标签的角色。
但是,在我们的密度估计问题中,$z^{(i)}$ 是未知的。所以我们可以做什么?
EM 算法是一个迭代算法,它有两个主要步骤。应用到我们的问题中,在 E 步骤中,它尝试去“猜” $z^{(i)}$ 的值。在 M 步骤中,它根据猜测的值更新模型的参数。因为在 M 步骤中我们假设第一步猜测的结果正确,最大化的过程就变得简单了。算法如下:
重复直到收敛:
(E 步骤)对每个 $i,j$,令
$$ w_j^{(i)} := p(z^{(i)} = j \mid x^{(i)}; \phi, \mu, \Sigma) $$(M 步骤)更新参数:
$$ \phi_j := \frac{1}{m} \sum_{i=1}^{m} w_j^{(i)}, $$$$ \mu_j := \frac{\sum_{i=1}^{m} w_j^{(i)}x^{(i)}}{\sum_{i=1}^{m} w_j^{(i)}}, $$$$ \Sigma_j := \frac{\sum_{i=1}^{m} w_j^{(i)}(x^{(i)} - \mu_j)(x^{(i)} - \mu_j)^T}{\sum_{i=1}^{m} w_j^{(i)}} $$
在 E 步骤中,我们利用 $x^{(i)}$ 和现在的参数计算参数 $z^{(i)}$ 的后验分布。即,利用贝叶斯法则,我们得到:
$$ p(z^{(i)} = j \mid x^{(i)}; \phi, \mu, \Sigma)= \frac{p(x^{(i)} \mid z^{(i)} = j; \mu, \Sigma)p(z^{(i)} = j; \phi)} {\sum_{l=1}^{k} p(x^{(i)} \mid z^{(i)} = l; \mu, \Sigma)p(z^{(i)} = l; \phi)} $$在 E 步骤中计算得到的 $w_j^{(i)}$ 表示我们对值 $z^{(i)}$ 的“软”猜测。
此外,你可以把 M 步骤的更新和 $z^{(i)}$ 已知时的公式作对比。他们是类似的,除了将表示每个点来自哪个高斯分布的示性函数 $1{z^{(i)} = j}$ 替换为 $w_j^{(i)}$。
EM 算法也让人联想起 $k$ 均值聚类算法,除了我们使用“软”赋值 $w_j^{(i)}$ 而不是“硬”赋值 $c(i)$。类似 $k$ 均值聚类,EM 算法也容易导致局部最优,所以用多个不同的初始值初始化可能是个好办法。
很明显 EM 算法对重复猜测 $z^{(i)}$ 的解释很自然;但它是如何产生的,并且我们是否能保证它的某个特效,例如收敛性?在下一部分的讲义中,我们对 EM 算法做一个更一般的解读,这将使我们更容易应用到有隐藏变量的估计问题中并且保证收敛。
EM 算法
在之前的讲义中,我们讨论了如何将 EM 算法应用到高斯混合模型的拟合。在这部分讲义中,我们将给出 EM 算法更广阔的视角,并且将展示如何将它应用到一大类有隐藏变量的估计问题。我们将从 Jeson 不等式开始讨论,这是个非常有用的结论。
Jeson 不等式
令 $f$ 是一个定义域为实数的函数。注意到 $f$ 是凸函数如果 $f’’(x) \ge 0$(对每个 $x \in \mathbb{R}$)。如果 $f$ 的输入是向量,那么上述条件就变为 $f$ 的 hessian 矩阵 $H$ 是半正定($H \ge 0$)。如果对每个 $x$,$f’’(x) > 0$,那么我们称 $f$ 是严格凸的(在向量情形,相应的陈述是 $H$ 为正定,写作 $H > 0$)。Jenson 不等式可以陈述如下:
定理
令 $f$ 为一个凸函数,$X$ 是一个随机变量,那么:
$$ \mathbb{E}[f(x)] \ge f(\mathbb{E}[X]) $$此外,如果 $f$ 是一个严格凸函数,那么 $\mathbb{E}[f(x)] = f(\mathbb{E}[X])$ 当且仅当 $X = \mathbb{E}[X]$ 以概率 1 成立(即 $X$ 是一个常数)。
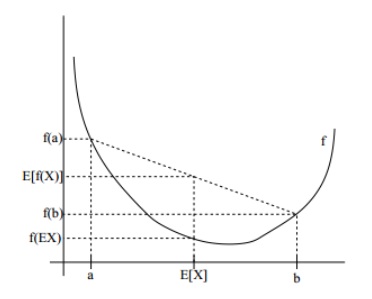
这里,$f$ 是实线所示的凸函数。此外,$X$ 是一个随机变量,有 0.5 的概率取 $a$,0.5 的概率取 $b$。因此,$X$ 的期望是 $a$ 和 $b$ 的中点。
我们还看到 $f(a), f(b)$ 和 $f(\mathbb{E}[X])$ 在 $y$ 轴上标记出来。此外,$\mathbb{E}[f(X)]$ 的值是 $f(a)$ 和 $f(b)$ 中点的 $y$ 坐标。从我们的例子中,可以看出如果 $f$ 是凸的,那么一定有 $\mathbb{E}[f(x)] \ge f[\mathbb{E}[X]]$。
注记
注意到如果 $f$ 是(严格)凹的当且仅当 $-f$ 是(严格)凸的(即 $f’’(x) \le 0$ 或 $H \le 0$)。Jenson 不等式对凹函数也正确,但是不等号反向。
EM 算法
假设我们有一个估计问题,训练集 ${x^{(i)}, \ldots, x^{(m)}}$ 有 $m$ 个独立样本。我们希望拟合模型 $p(x,z)$ 的参数,似然函数如下
$$ l(\theta) = \sum_{i=1}^{m} \log p(x; \theta) = \sum_{i=1}^{m} \log \sum_z \log p(x,z; \theta) $$但是,准确找到参数 $\theta$ 的最大似然估计可能很难。这里 $z^{(i)}$ 是隐藏变量;通常的情形是,如果 $z^{(i)}$ 被观测到了,那么最大似然估计将会很简单。
在这种情形下,EM 算法给出一个处理最大似然估计的有效方法。准确地最大化 $l(\theta)$ 可能很难,我们的策略是取而代之的构造一个 $l$ 的下界(E 步骤),然后优化下界(M 步骤)。
对每个 $i$,令 $Q_i$ 是关于 $z$ 的某个分布($\sum_z Q_i(z)=1, Q_i(z)\ge 0$),考虑下式
$$ \sum_i \log p(x^{(i)}; \theta)= \sum_i \log \sum_{z^{(i)}} p(x^{(i)}, z^{(i)}; \theta) \tag{1} $$$$ = \sum_i \log \sum_{z^{(i)}} Q_i(z^{(i)}) \frac{p(x^{(i)}, z^{(i)}; \theta)}{Q_i(z^{(i)})} \tag{2} $$$$ \ge \sum_i \sum_{z^{(i)}} Q_i(z^{(i)}) \log \frac{p(x^{(i)}, z^{(i)}; \theta)}{Q_i(z^{(i)})} \tag{3} $$最后一步利用了 Jeson 不等式。特别地,$f(x)=\log x$ 是一个凹函数,因为在它的定义域 $x \in \mathbb{R}^+$ 上 $f’’(x) = -\frac{1}{x^2} < 0$。此外,如下求和式
$$ \sum_{z^{(i)}} Q_i(z^{(i)}) \left[\frac{p(x^{(i)}, z^{(i)}; \theta)}{Q_i(z^{(i)})}\right] $$是因于 $\left[\frac{p(x^{(i)}, z^{(i)}; \theta)}{Q_i(z^{(i)})}\right]$ 关于 $z^{(i)}$ 的期望,$z^{(i)}$ 的分布是由 $Q_i(z^{(i)})$ 确定的。根据 Jeson 不等式,我们有
$$ f\left(\mathbb{E}_{z^{(i)} \sim Q_i}\left[\frac{p(x^{(i)}, z^{(i)}; \theta)}{Q_i(z^{(i)})}\right]\right)\ge\mathbb{E}_{z^{(i)} \sim Q_i}\left[ f\left(\frac{p(x^{(i)}, z^{(i)}; \theta)}{Q_i(z^{(i)})}\right) \right] $$其中 $z^{(i)} \sim Q_i$ 表示期望是关于从分布 $Q_i$ 抽取的 $z^{(i)}$ 得来的。这允许我们从公式(2)推导到公式(3)。
现在,对任意分布 $Q_i$,上述不等式给出一个 $l(\theta)$ 的下界。关于 $Q_i$:由很多种选择,应该选择哪个呢?如果我们对参数 $\theta$ 有一些猜测,很自然地想到选择使得下界尽可能紧的 $Q_i$。即,我们将使得在 $\theta$ 处上述不等号取等号。(后面我们将看到,随着 EM 算法的迭代,$l(\theta)$ 单调递增。)
为了使对某个特定的 $\theta$,下界更紧,我们需要涉及 Jenson 不等式的地方取等号。为了这个条件成立,我们知道只要期望是关于“常”随机变量取的即可。即,我们需要:
$$ \frac{p(x^{(i)}, z^{(i)}; \theta)}{Q_i(z^{(i)})} = c $$对某个不依赖的 $z^{(i)}$ 的常数 $c$ 成立。这可以通过如下选择完成
$$ Q_i(z^{(i)}) \propto p(x^{(i)}, z^{(i)}; \theta) $$事实上,既然我们已知 $\sum_i Q_i(z^{(i)}) = 1$,上式事实上告诉我们
$$ Q_i(z^{(i)})= \frac{p(x^{(i)}, z^{(i)}; \theta)}{\sum_z p(x^{(i)}, z; \theta)}= \frac{p(x^{(i)}, z^{(i)}; \theta)}{p(x^{(i)}; \theta)}= p(z^{(i)} \mid x^{(i)}; \theta) $$因此,在给定 $x^{(i)}$ 和 $\theta$ 的条件下,我们只要把 $Q_i$ 设置为 $z^{(i)}$ 的后验分布即可。
现在,对于这样 $Q_i$ 的选择,上述不等式给出我们尝试最大化的对数似然的下界。这是 E 步骤。在 M 步骤中,我们最大化上述下界来获得新的参数 $\theta$。重复这两个步骤就给出了 EM 算法,叙述如下:
重复直到收敛:
(E 步骤)对每个 $i$,令
$$ Q_i(z^{(i)}) = p(z^{(i)} \mid x^{(i)}; \theta) $$(M 步骤)令
$$ \theta := \arg\max_{\theta} \sum_i \sum_{z^{(i)}} Q_i(z^{(i)}) \log \frac{p(x^{(i)}, z^{(i)}; \theta)}{Q_i(z^{(i)})} $$