
线性回归
有如下数据集
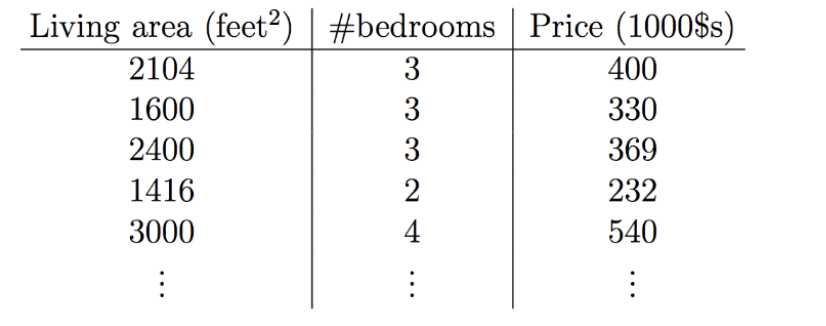
在上图中,输入特征$x$是$\mathbb{R}^2$范围取值的一个二维向量,$x_1^{(i)}$就是训练集中第$i$个房屋的面积,而$x_2^{(i)}$就是训练集中第$i$个房屋的我是数量,这只是举个例子,设计算法的时候你可以自己设计特征量
然后我们可以把$y$假设为一个以$x$为变量的线性函数
$$ h_\theta(x)=\theta_0+\theta_1x_1+\theta_2x_2 $$这里的$\theta_i$是参数,也叫权重,是从$X$到$Y$的线性函数映射的空间参数,在不引起混淆的情况下可以把$h_\theta(x)$中的$\theta$省略,另外,为了简化我们设$x_0=1$,简化后就有
$$ h(x)=\sum_{i=0}^{n} \theta x_i=\theta^T x $$等式最右边的$\theta$和$x$都是向量,$x$是输入变量的个数(就是特征量个数)
现在,给定了一个训练集,我们该如何挑选参数$\theta$,一个看上去比较合理的方法是让$h(x)$尽量逼近$y$,若是要用公式的形式来表示,就要定义一个函数,由此来衡量对于每个不同的$\theta$值,$h(x^{(i)})$与对应的$y^{(i)}$的距离,用如下的方式定义了一个成本函数
$$ J(\theta)=\frac{1}{2}\sum_{i=1}^{n}{(h_\theta(x^{(i)})-y^{(i)})^2} $$你会发现这个函数和常规最小二乘法拟合模型中的最小二乘法成本函数非常相似
最小均方算法(LMS)
我们要让$J(\theta)$最小,我们考虑用梯度下降法,这个方法就是从某一个$\theta$的初始值开始,然后逐渐重复更新
$$ \theta_j:=\theta_j-\alpha \frac{\partial}{\partial \theta_j} J{(\theta)} $$在这个式子中,$\alpha$是学习率
要实现这个算法,我们要知道右边的导数项是什么,让我们来计算一下
$$ \begin{align*} \frac{\partial}{\partial \theta_j} J(\theta) &= \frac{\partial}{\partial \theta_j} \frac{1}{2}(h_\theta(x) - y)^2 \\[6pt] &= (h_\theta(x) - y)\, \frac{\partial}{\partial \theta_j}(h_\theta(x) - y) \\[6pt] &= (h_\theta(x) - y)\, \frac{\partial}{\partial \theta_j}\left(\sum_{i=0}^n \theta_i x_i - y\right) \\[6pt] &= (h_\theta(x) - y)\, x_j \end{align*} $$对单个训练样本,更新规则如下:
$$ \theta_j := \theta_j + \alpha \left( y^{(i)} - h_\theta(x^{(i)}) \right) x_j^{(i)} $$这个规则也称为LMS更新规则,也称为Widrow-Hoff学习规则,具体的算法如下
重复直到收敛{
对每个$j$:
$$ \theta_j:=\theta_j+\alpha\sum_{i=1}^m{(y^{(i)}-h_\theta(x^{(i)}))} $$}
这个方法叫做批量梯度下降法(batch gradient descent),此外还有一种方法
Loop{
for i=1 to m{
对每个$j$:
$$ \theta_j := \theta_j + \alpha(y^{(i)}-h_{\theta}(x^{(i)}))x_j^{(i)} $$ }
}
这个算法叫做随机梯度下降法(SGD)
在批量梯度下降算法中,我们要扫描整个训练集,才会更新一次,当数据集的量非常庞大的时候,会有很大计算量,而随机梯度下降算法在遇到训练样本的时候仅根据该单个训练样本的误差梯度更新参数,所以随机梯度下降往往比批量梯下降更快接近最小值。
注意,它可能不会收敛到最小值,$\theta$会在$J(\theta)$的最小值附近震荡
正规方程
这是第二种方法,这种方法中我们通过求导让导数等于0的方式找到取得最小值的地方,给定一个训练集,把设计矩阵$X$设置为一个$x*n$的矩阵(实际上是$m * (n + 1)$,如果包含截距项),该矩阵的每行是个训练样本
$$ X = \begin{bmatrix} -(x^{(1)})^{T}- \\ -(x^{(2)})^T- \\ \vdots \\ -(x^{(m)})^T- \end{bmatrix} $$另外,令 $\vec{y}$ 为包含训练集中所有目标值的 $m$ 维向量:
$$ \vec{y} = \begin{bmatrix} y^{(1)} \\ y^{(2)} \\ \vdots \\ y^{(m)} \end{bmatrix} $$由于 $h_\theta(x^{(i)}) = (x^{(i)})^T \theta$,我们可以很容易地验证:
关于$\theta$求梯度我们就可以得到:
$$ \begin{align*} \nabla_\theta J(\theta) &= \nabla_\theta \frac{1}{2} (X\theta - \vec{y})^T (X\theta - \vec{y}) \\[6pt] &= \frac{1}{2} \nabla_\theta (\theta^T X^T X \theta - \theta^T X^T \vec{y} - \vec{y}^T X \theta + \vec{y}^T \vec{y}) \\[6pt] &= \frac{1}{2} \nabla_\theta (\theta^T X^T X \theta - 2\theta^T X^T \vec{y}) \\[6pt] &= \frac{1}{2} (2 X^T X \theta - 2 X^T \vec{y}) \\[6pt] &= X^T X \theta - X^T \vec{y} \end{align*} $$第四个等号利用了
$$ \nabla_\theta (\theta^T A \theta) = (A + A^T)\theta $$$$ \nabla_\theta (\theta^T x) = x $$令梯度为 0 可得 正规方程:
$$ X^T X \theta = X^T \vec{y} $$因此,通过等式以解析形式给出使$J(\theta)$最小化的 $\theta$ 的值:
$$ \theta = (X^T X)^{-1} X^T \vec{y} $$