核方法
回到我们对线性回归的讨论中,我们遇到了一个问题,其中输入 $x$ 是房子的生活区域。我们考虑使用特征 $x^2$ 和 $x^3$ 进行回归以获得二次函数。为了区分这两组变量,我们将“原始”输入值称为问题的输入属性(在本例中为 $x$,生活区域)。当它被映射到一组新的最终传递给学习算法时,我们将这些新的量称为输入特征。(不幸的是,不同的作者使用不同的术语来描述这两件事,但是我们将在这份讲义中一致地使用这个术语。)我们还将 $\phi$ 表示特征映射,它将属性映射到特征。例如,在我们的例子中,我们有:
$$ \phi(x) = \begin{bmatrix} x \\ x^2 \\ x^3 \end{bmatrix} $$我们可能想使用某些特征 $\phi(x)$ 来学习,而不是使用原始输入属性 $x$ 来使用 SVM。要做到这一点,我们只需要检查我们之前的算法,并用 $\phi(x)$ 替换其中的 $x$。
由于算法可以完全根据内积 $\langle x, z \rangle$ 编写,这意味着我们将用 $\langle \phi(x), \phi(z) \rangle$ 替换所有这些内积。特别地,给定特征映射 $\phi$,我们将相应的核定义为:
$$ K(x, z) = \phi(x)^T \phi(z) $$然后,在我们之前在算法中有 $\langle x, z \rangle$ 的地方,我们可以简单地用 $K(x, z)$ 替换它。我们的算法现在将在使用特征 $\phi$ 的情况下学习。
现在,给定 $\phi$,我们可以通过计算 $\phi(x)$ 和 $\phi(z)$ 并求其内积来计算 $K(x, z)$。但更有趣的是,通常,$K(x, z)$ 的计算成本可能非常低廉,即使 $\phi(x)$ 本身的计算成本非常高(可能因为它是一个维数很高的向量)。在这样的情况下,通过使用高效算法计算 $K(x, z)$,我们可以使 SVM 在给出的高维特征空间中学习,但同时不需要显式地计算 $\phi(x)$。
来看一个例子。假设 $x, z \in \mathbb{R}^n$,并考虑:
$$ K(x, z) = (x^T z)^2 $$上式也可以写为
$$ \begin{aligned} K(x, z) &= \left( \sum_{i=1}^{n} x_i z_i \right) \left( \sum_{j=1}^{n} x_j z_j \right) \\ &= \sum_{i=1}^{n} \sum_{j=1}^{n} x_i x_j z_i z_j \\ &= \sum_{i,j=1}^{n} (x_i x_j)(z_i z_j) \end{aligned} $$因此,我们看到 $K(x, z) = \phi(x)^T \phi(z)$,其中的特征映射(此处针对 $n=3$ 的情况给出)为:
$$ \phi(x) = \begin{bmatrix} x_1 x_1 \\ x_1 x_2 \\ x_1 x_3 \\ x_2 x_1 \\ x_2 x_2 \\ x_2 x_3 \\ x_3 x_1 \\ x_3 x_2 \\ x_3 x_3 \end{bmatrix} $$注意,虽然计算 $\phi(x)$ 需要 $O(n^2)$ 的时间,但是计算 $K(x, z)$ 只需要 $O(n)$ 时间——和输入属性的维度呈线性关系。
对于相关的核,考虑:
$$ \begin{aligned} K(x, z)&= (x^T z + c)^2 \\&= \left( \sum_{i=1}^{n} x_i z_i + c \right)^2 \\&= \sum_{i,j=1}^{n} (x_i x_j)(z_i z_j)+ \sum_{i=1}^{n} (\sqrt{2c}\, x_i)(\sqrt{2c}\, z_i)+ c^2 \end{aligned} $$相应的特征映射为(再次给出 $n = 3$ 的情形)
$$ \phi(x) = \begin{bmatrix} x_1 x_1 \\ x_1 x_2 \\ x_1 x_3 \\ x_2 x_1 \\ x_2 x_2 \\ x_2 x_3 \\ x_3 x_1 \\ x_3 x_2 \\ x_3 x_3 \\ \sqrt{2c}\, x_1 \\ \sqrt{2c}\, x_2 \\ \sqrt{2c}\, x_3 \\ c \end{bmatrix} $$参数 $c$ 控制 $x_i$(一阶)和 $x_i x_j$(二阶)项之间的相对权重。
进一步推广,核
$$ K(x, z) = (x^T z + c)^d $$对应于映射到 $\binom{n+d}{d}$ 维特征空间的特征映射,对应于形式为 $x_{i_1} x_{i_2} \dots x_{i_d}$ 的所有次数最多为 $d$ 的单项式。然而,尽管在这个 $O(n^d)$ 维空间中,计算 $K(x, z)$ 仍然只需要 $O(n)$ 的时间,因此我们永远不需要在这个非常高维的特征空间中明确地表示特征向量。
现在,让我们从不同的角度谈论核。直观地,如果 $\phi(x)$ 和 $\phi(z)$ 靠得很近,那么我们可以期望
$$ K(x, z) = \phi(x)^T \phi(z) $$很大。相反,如果 $\phi(x)$ 和 $\phi(z)$ 相距很远,比如几乎彼此正交,则
$$ K(x, z) = \phi(x)^T \phi(z) $$将很小。因此,我们可以将 $K(x, z)$ 视为对 $\phi(x)$ 和 $\phi(z)$ 或者 $x$ 和 $z$ 之间相似度的度量。
鉴于这种直觉,假设对于你正在研究的一些学习问题,你已经提出了某个函数 $K(x, z)$,你认为它可能是 $x$ 和 $z$ 相似程度的合理度量。例如,也许你选择了
$$ K(x, z) = \exp \left( - \frac{\lVert x - z \rVert^2}{2\sigma^2} \right) $$这是 $x$ 和 $z$ 相似性的合理度量,当 $x$ 和 $z$ 接近时,上式接近 $1$,当 $x$ 和 $z$ 相距很远时,上式接近 $0$。我们可以将这个 $K$ 用作 SVM 中的核吗?在这个特定的例子中,答案是肯定的。(这个内核称为高斯核,对应于无限维特征映射。)
更一般地说,给定某个函数 $K$,我们如何判断它是否是一个有效的核;即,我们如何判断是否存在某个特征映射 $\phi$,使得对于所有 $x, z$,都有
$$ K(x, z) = \phi(x)^T \phi(z) $$现在假设 $K$ 确实对应于某个特征映射 $\phi$ 的有效核。现在,考虑有限的 $m$ 点(不一定是训练集)${x^{(1)}, \dots, x^{(m)}}$,并且定义 $m \times m$ 矩阵 $K$,使得其第 $(i, j)$ 个元素为 $K(x^{(i)}, x^{(j)})$。该矩阵称为核矩阵。请注意,由于核函数 $K(x, z)$ 和核矩阵 $K$ 之间存在明显的密切关系,我们经常滥用符号使用 $K$ 来表示核函数 $K(x, z)$ 和核矩阵 $K$。
现在,如果 $K$ 是有效的核,则
$$ K_{ij}= K(x^{(i)}, x^{(j)})= \phi(x^{(i)})^T \phi(x^{(j)})= \phi(x^{(j)})^T \phi(x^{(i)})= K(x^{(j)}, x^{(i)})= K_{ji} $$因此 $K$ 是对称矩阵。更重要的是,令 $\phi_k(x)$ 表示向量 $\phi(x)$ 的第 $k$ 个坐标,我们发现对于任何向量 $z$,我们都有
$$ \begin{aligned} z^T K z&= \sum_i \sum_j z_i K_{ij} z_j \\&= \sum_i \sum_j z_i \phi(x^{(i)})^T \phi(x^{(j)}) z_j \\&= \sum_i \sum_j z_i \sum_k \phi_k(x^{(i)}) \phi_k(x^{(j)}) z_j \\&= \sum_k \sum_i \sum_j z_i \phi_k(x^{(i)}) \phi_k(x^{(j)}) z_j \\&= \sum_k \left( \sum_i z_i \phi_k(x^{(i)}) \right)^2 \\&\ge 0 \end{aligned} $$由于 $z$ 是任意的,这表明 $K$ 是半正定的($K \ge 0$)。
因此,我们已经证明,如果 $K$ 是有效核(即,如果它对应于某些特征映射 $\phi$),则相应的核矩阵 $K \in \mathbb{R}^{m \times m}$ 是半正定对称矩阵。更一般地说,这不仅是 $K$ 成为有效核(也称为 Mercer 核)的必要条件,而且是充分条件。以下结果归功于 Mercer。
定理(Mercer)
设 $K \in \mathbb{R}^n \times \mathbb{R}^n \to \mathbb{R}$。那么 $K$ 是有效(Mercer)核的充要条件是对任意 ${x^{(1)}, \dots, x^{(m)}}$($m < \infty$),相应的核矩阵是正半定对称矩阵。
给定函数 $K$,除了试图找到与其对应的特征映射 $\phi$ 之外,该定理还提供了另一种测试它是否是有效核的方法。
核在支持向量机方面的应用应该已经很清楚了,所以我们不会在这里花太多时间。但请记住,核的概念比 SVM 具有更广泛的适用性。具体来说,如果你有任何学习算法只需要输入属性向量之间的内积 $\langle x, z \rangle$ 来编写,那么用 $K(x, z)$ 替换它,其中 $K$ 是一个核,你可以“神奇地”允许你的算法在对应于 $K$ 的高维特征空间中有效地工作。例如,该技巧可以与感知机一起应用以导出核感知机算法。我们将在本课程后面看到的许多算法也适用于这种方法,后者被称为“核技巧”。
正则化和不可分的情形
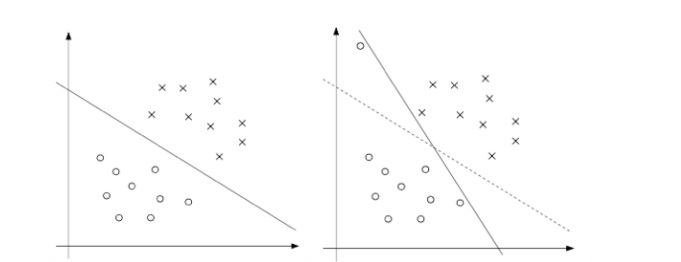
到目前为止所呈现的 SVM 的推导都是假设数据是线性可分的。虽然通过将数据映射到高维特征空间通常会增加数据可分的可能性,但我们无法保证它始终如此。此外,在某些情况下,我们并不希望找到分离超平面是我们想要的,因为这可能容易受到异常值的影响。例如,下图左边显示了一个最佳间隔分类器,当在左上角区域(右图)中添加了一个异常值时,它会使决策边界产生戏剧性的移动,并且得到的分类器的间隔小得多。
为了使算法适用于线性不可分数据集以及对异常值不太敏感,我们重新设置我们的优化问题(使用 $\ell_1$ 正则化),如下所示:
$$ \begin{aligned} \min_{w,b,\xi} \quad & \frac{1}{2} \lVert w \rVert^2 + C \sum_{i=1}^{m} \xi_i \\ \text{s.t.} \quad & y^{(i)} (w^T x^{(i)} + b) \ge 1 - \xi_i, \quad i = 1, \dots, m \\ & \xi_i \ge 0, \quad i = 1, \dots, m \end{aligned} $$因此,现在允许样本具有小于 $1$ 的(函数)间隔,并且如果某样本具有函数间隔 $1 - \xi_i$($\xi_i > 0$),则我们付出的代价为目标函数的成本增加 $C \xi_i$。参数 $C$ 控制了使 $\lVert w \rVert^2$ 变小(我们之前看到的这项使间隔变大)和确保大多数样本具有至少 $1$ 的函数间隔的双重目标之间的相对权重。
将上述条件修改为
$$ \begin{aligned} 1 - \xi_i - y^{(i)} (w^T x^{(i)} + b) &\le 0, \quad i = 1, \dots, m \\ -\xi_i &\le 0, \quad i = 1, \dots, m \end{aligned} $$我们可以得到拉格朗日算子
$$ \begin{aligned} \mathcal{L}(w,b,\xi,\alpha,r)&= \frac{1}{2} \lVert w \rVert^2+ C \sum_{i=1}^{m} \xi_i \\&\quad - \sum_{i=1}^{m} \alpha_i \big[ y^{(i)} (w^T x^{(i)} + b) - 1 + \xi_i \big]- \sum_{i=1}^{m} r_i \xi_i \end{aligned} $$这里,$\alpha_i$ 和 $r_i$ 是我们的拉格朗日乘子(约束为 $\ge 0$)。求偏导并令其为 $0$ 可得:
$$ \nabla_w \mathcal{L}(w,b,\xi,\alpha,r)= w - \sum_{i=1}^{m} \alpha_i y^{(i)} x^{(i)} = 0 $$$$ \nabla_b \mathcal{L}(w,b,\xi,\alpha,r)= \sum_{i=1}^{m} \alpha_i y^{(i)} = 0 $$$$ \nabla_{\xi_i} \mathcal{L}(w,b,\xi,\alpha,r)= C - \alpha_i - r_i = 0 $$化简第一个式子可得
$$ w = \sum_{i=1}^{m} \alpha_i y^{(i)} x^{(i)} $$带入原式可得
$$ \begin{aligned} \mathcal{L}(w,b,\xi,\alpha,r)&= \sum_{i=1}^{m} \alpha_i- \frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} y^{(i)} y^{(j)} \alpha_i \alpha_j (x^{(i)})^T x^{(j)} \\ &\quad - b \sum_{i=1}^{m} \alpha_i y^{(i)}+ \sum_{i=1}^{m} (C - \alpha_i - r_i) \xi_i \end{aligned} $$注意到
$$ \sum_{i=1}^{m} \alpha_i y^{(i)} = 0, \qquad \alpha_i + r_i = C $$所以
$$ \mathcal{L}(w,b,\xi,\alpha,r)= \sum_{i=1}^{m} \alpha_i- \frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} y^{(i)} y^{(j)} \alpha_i \alpha_j (x^{(i)})^T x^{(j)} $$由 $\xi_i \ge 0$ 且 $r_i \ge 0$ 可得
$$ \alpha_i \le C, \qquad \alpha_i \ge 0 $$因此对偶问题为
$$ \begin{aligned} \max_{\alpha} \quad W(\alpha)&= \sum_{i=1}^{m} \alpha_i- \frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} y^{(i)} y^{(j)} \alpha_i \alpha_j (x^{(i)})^T x^{(j)} \\ \text{s.t.} \quad & 0 \le \alpha_i \le C, \quad i = 1, \dots, m \\ & \sum_{i=1}^{m} \alpha_i y^{(i)} = 0 \end{aligned} $$和以前一样,我们像公式 (9) 那样用 $\alpha$ 表示 $w$。这样在求解对偶问题后,我们可以继续使用公式 (13) 进行预测。注意,在添加 $\ell_1$ 正则化后,对偶问题的唯一变化是原来的约束 $0 \le \alpha_i$ 现在变为 $0 \le \alpha_i \le C$;注意此时 $b$ 的计算也必须修改。
此外,KKT 对偶互补条件(在下一节中将有助于测试 SMO 算法的收敛)是:
$$ \alpha_i = 0 \;\Rightarrow\; y^{(i)} (w^T x^{(i)} + b) \ge 1 \tag{14} $$$$ \alpha_i = C \;\Rightarrow\; y^{(i)} (w^T x^{(i)} + b) \le 1 \tag{15} $$$$ 0 < \alpha_i < C \;\Rightarrow\; y^{(i)} (w^T x^{(i)} + b) = 1 \tag{16} $$上述等式的证明如下:
首先由上一讲的等式可得互补条件
$$ \alpha_i \big( 1 - \xi_i - y^{(i)} (w^T x^{(i)} + b) \big) = 0 $$以及
$$ r_i \xi_i = 0 $$并且有
$$ 1 - \xi_i - y^{(i)} (w^T x^{(i)} + b) \le 0, \qquad \xi_i \ge 0 $$如果 $\alpha_i = 0$,则由
$$ \alpha_i + r_i = C $$可得
$$ r_i = C $$因此 $r_i > 0$,由 $r_i \xi_i = 0$ 得
$$ \xi_i = 0 $$由约束
$$ 1 - \xi_i - y^{(i)} (w^T x^{(i)} + b) \le 0 $$可得
$$ y^{(i)} (w^T x^{(i)} + b) \ge 1 $$如果 $\alpha_i = C$,则
$$ r_i = C - \alpha_i = 0 $$此时由
$$ \alpha_i \big( 1 - \xi_i - y^{(i)} (w^T x^{(i)} + b) \big) = 0 $$且 $\alpha_i = C > 0$,得到
$$ 1 - \xi_i - y^{(i)} (w^T x^{(i)} + b) = 0 $$即
$$ y^{(i)} (w^T x^{(i)} + b) = 1 - \xi_i \le 1 $$如果 $0 < \alpha_i < C$,则由
$$ \alpha_i + r_i = C $$可知
$$ r_i > 0 $$由 $r_i \xi_i = 0$ 得
$$ \xi_i = 0 $$再由
$$ \alpha_i \big( 1 - \xi_i - y^{(i)} (w^T x^{(i)} + b) \big) = 0 $$且 $\alpha_i > 0$,得到
$$ 1 - \xi_i - y^{(i)} (w^T x^{(i)} + b) = 0 $$因为 $\xi_i = 0$,于是
$$ y^{(i)} (w^T x^{(i)} + b) = 1 $$现在,剩下的就是给出一个实际解决对偶问题的算法,我们将在下一节中介绍。